User Manual

The following user manual addresses each of the tools separately, though they are designed to complement each other.
GIS Site Locator Tool
Description
What is Low Impact Development and why do we need it?
In natural landscapes such as open space grasslands or forested areas, when rainfall occurs, some of it is intercepted by vegetation and evaporated off again and some of it soaks into the soil and replenishes soil moisture and groundwater reserves providing flows in creeks and rivers. In contrast, urban drainage systems have very low interception and groundwater recharge capacity and are designed to capture runoff from impervious surfaces and pipe it through a distributed network away from people, roads, and other urban infrastructure. Soil moisture is replenished by irrigation usually using potable water supply. Because urban pollutants are also found on impervious surfaces, pollutants are also inadvertently conveyed into collection systems and away from the urban system without treatment during rain storms (or due to irrigation overflows) leading to the pollution of urban creeks and rivers and nearby lakes, estuaries and coastal water bodies.
Low impact development (LID) or Green Infrastructure (GI) are somewhat synonymous terms for greening or “botanizing” cityscapes through city planning efforts, infrastructure upgrades, and new/ redevelopment so that they mimic more natural landscapes. This is achieved through slowing, spreading, and infiltrating (sinking) urban stormwater run-off thus reducing stormwater peak flow and volume and potentially providing effective treatment of urban pollutants. There are different kinds of GI that incorporate mechanisms for slowing, spreading, and helping stormwater to soak into the ground. These mechanisms include slowing water velocities (adding roughness), detaining stormwater in vaults, ponds or depressed areas, retaining stormwater allowing sedimentation and reuse of captured volume (landscape irrigation or toilet flushing are examples), filtering stormwater through porous media (e.g. sand or other man-made filters and pervious pavement), infiltrating stormwater into the ground, and methods to treat stormwater such as the addition of activated carbon or the harvest of vegetation that is primarily nourished from nutrients in stormwater. Since GI is now included in many stormwater permits for both flow and water quality control, it is important to place it in the urban landscape in the most beneficial locations with the least cost.
Notwithstanding these immensely important water quality and quantity benefits, GI also provides a number of other benefits including helping to improve air quality and reduce greenhouse gases, heat island mitigation, traffic calming and helping to improve the bike/pedestrian environment, adding and connecting green spaces (and habitats for birds and wildlife) and helping to beautify neighborhoods and increase property values. These features help to connect the public with natural environmental processes leading to greater community involvement and caring for the cityscape. In many cases, it is these features, rather than water quantity and quality benefits, that primarily drive the community decision making process around inclusion of GI into redevelopment projects.
GreenPlan-IT Tool Overview
The GreenPlan-IT Site Locator Tool is designed as a planning level tool to identify (and rank based on user input) feasible locations for placement of GI features in municipal areas within the California Regional Water Quality Control Board, Region 2 (San Francisco Bay) jurisdiction. The output from the tool can be used by municipal staff and their consultants as the basis for determining the most cost effective and worthwhile locations for GI placement. Outputs can be included in various planning documents such as parks and recreations plans, capital improvement plans, redevelopment plans, or re-envisioning documents in relation to “complete streets”. Although the present version focuses quantitatively on water quality and quantity, the other ancillary benefits can be qualitatively included through the ranking components described below and discussed in the individual case studies sections. It is hoped that future iterations of the Toolkit will include quantitative modules for these other benefits. Until that time, the present version of the GreenPlan-IT tool includes the following nine (9) GI feature types:
- Bioretention (with and without an underdrain as two different types) cells are small, vegetated, shallow depressions that serve to filter stormwater from impervious surfaces during rainfall events. Pollutants are removed from stormwater through adsorption, microbial activity, plant uptake, sedimentation, and filtration. Bioretention with out underdrains are more suitable to areas with higher soil filtration rates.

Figure 1. Bioretention unit on Osgood Road in Fremont, California (Source: Alicia Gilbreath)
- Infiltration trenches are narrow trenches that have been back-filled with stone. Runoff is collected during storm events and stored in the void spaces of the gravel before being released back into the soil by infiltration.

Figure 2. Infiltration Trench (Source: GI Definitions and Details, J. Walker).
- Permeable pavement, or pervious pavement, is a porous surface laid over uniformly graded stones. It reduces runoff volume, peak discharge rates, pollutant loading, and runoff temperature.

Figure 3. Permeable pavement on Allston St., Berkeley, CA (Source: courtesy of Berkeleyside).
- Storm water wetlands collect runoff and store it in a permanent pool. Stormwater runoff drains into these wetlands and the plants and soils act as a filter for the stormwater.

Figure 4. Storm water wetlands (Source: GI Definitions and Details, J. Walker).
- Vegetated swales are broad, shallow channels with dense vegetation covering the sides of the slopes and bottom. They are designed to slow stormwater runoff and filter out particulate pollutants, and promote infiltration before reaching the stormwater drain.

Figure 5. Vegetated swale in Moss Beach, San Mateo County, California (Source: Nicole David)
- Wet ponds are used instead of a dry detention basin to provide flood control with enhanced amenities and aesthetics and improved pollutant removal. A wet pond provides similar benefits to stormwater wetlands, except they are typically deeper and may increase the temperature of runoff.

Figure 6. Wet pond (Source: GI Definitions and Details, J. Walker).
- Flow Through Planter boxes are bioretention systems with an impermeable lining. Water stored in the planter box is disharged through a pipe not through infiltration of native soils.
Figure 7. Flow Through Planter.
- Tree Well boxes are small-scale bioinfiltration systems that are highly adaptable for small places. Tree wells are designed to collect runoff to allowing excess water to infiltrate into native soil or be collected by an underdrain.

Figure 8. Tree well example by Filtera.
Site Locator Tool User Inputs
When using the Site Locator Tool, you have the option of using three (3) data input combinations (inputs are detailed below):

Regional Base Analysis
The regional base analysis component of the tool was developed by SFEI in 2011 via a grant received through the Critical Coastal Areas (CCA) program, and provides a map of suitable GI areas as a starting point for further analyses. This analysis has been more recently run to create regional suitability layers for the additional GI types. The regional base analysis output is provided in the GreenPlan-IT Site Locator Tool (in the file geodatabase base_analysis.gdb in the “data” folder).
For each GI feature type, identification of suitable locations in the regional base analysis was based on the following factors:
- Depth to water table
- Slope
- Hydrologic soil type
- Land use
- Liquefaction risk
- Surface imperviousness
Each factor was binned into groups that represented more or less suitable conditions for each GI type. These rankings were then weighted and used in a Categorical Weighted Overlay to identify locations that were suitable for each GI type.
Users may incorporate the base analysis provided either as an initial screening of suitable areas or during the ranking procedures (described below) but there are pros and cons. For example, incorporating the base analysis in the initial screening process provides a more refined (but exclusive) output since only locations that were deemed to be most suitable by the base analysis are included. Incorporating the base analysis in the ranking process provides a final output that is more inclusive of potential GI locations, and the results will not be limited to locations deemed suitable by the base analysis; rather, locations within the base analysis will receive a higher ranking than those not specified in the base analysis. This may be more desirable as many of the factors that were used to create the base analysis layer can be addressed by engineering and or design. That is, locations outside of the base analysis may still be possible locations for GI, however they may be more costly to install in those locations due to additional engineering and installation requirements (terracing due to slope, underdrain due to non-ideal soil type etc.). A city or county interested in saving costs by installing regionally applicable standard GI designs may need to take these issues into account when running the tool.
Refining Analyses
Municipalities may choose to adopt the base analysis as the sole input to their planning documents (not recommended in most circumstances) or to develop a refined analysis using additional regional datasets (provided with the GreenPlan-IT Site Locator Tool) and/or their own compilation of local city datasets. As with any simple model of a complex landscape, the scale and accuracy of input data will largely determine the scale and accuracy of the interpretative outputs. Therefore, when local higher quality data are available, we recommend these be incorporated. There are four (4) modules that may be used to facilitate a more refined analysis using available local data to improve the scale and accuracy (and relevance) of the tool outputs. These are:
- Locations Analysis
- Ownership Analysis
- Local Opportunities and Constraints Analysis
- Knockout Analysis
These modules are described in the following table and address weaknesses that would ensue if just the regional base analysis were to be used for planning feasible LID locations.

Regional Datasets
Regional datasets (in the file geodatabase RegionalDatasets.gdb in the “data” folder) are a collection of publicly available and SFEI-generated datasets that may be used in the Location, Ownership, Opportunities and Constraints, and/or Knockout Analysis modules.
See here for a description of the regional datasets provided.
Local Datasets
If municipality-specific data are available, users may choose to include these data in the Location, Ownership, Opportunities and Constraints, and/or Knockout Analysis modules.
See Tool Preparation, I. Compiling Local Datasets.
Introduction to File Structure and Necessary File Types
- Download the SiteLocatorTool_GreenPlanIT_SFEI.zip here.
- Navigate to the SiteLocatorTool_GreenPlanIT_SFEI.zip; right-click on the zip file→Extract All…→Extract the contents to a folder.
- If you would like to store the tool elsewhere, move the extracted folder and its contents to your desired location.
SFEI has provided the GreenPlan-IT Site Locator tool (with ancillary files), the regional base analysis, and the regional datasets in a preset folder schema, as shown below. If using local datasets, the user should reference the folder schema to determine the locations and formats of any compiled data. This will be described in detail in Tool Preparations.

Tool Preparations
If you will not be using regional datasets (provided) or local datasets, skip to Run Tool: 1 – Site Locator Tool.
If you will not be using local datasets, skip to Tool Preparations, Preparing Analysis Tables.
If you will be using local datasets, continue with the next step which is compiling data sets.
Compiling Datasets
- Create a new file geodatabase for your local datasets in the “data” folder.
- We recommend renaming your file geodatabase using the convention YourMunicipalityNameDatasets.gdb (i.e. ContraCostaDatasets.gdb).
- Save/export any relevant datasets to this new file geodatabase.
- The default spatial reference used by the GreenPlan-IT Site Locator Tool is NAD 1983 California Teale Albers (EPSG: 3310). As a best practice, we recommend projecting any local datasets to this spatial reference; however, this is not a requirement.
Preparing Analysis Tables
When preparing to run the GreenPlan-IT Site Locator Tool, the user will be required to specify if any additional refined analyses (Location, Ownership, Opportunities and Constraints, and/or Knockout Analysis) will be used. The user may select any combination of refined analyses when running the GreenPlan-IT Site Locator Tool (i.e. any combination of 0 - 4 analyses).
If using any of these additional refined analyses (Location, Ownership, Opportunities and Constraints, and/or Knockout Analysis), the user will be required to provide an accompanying table (templates provided by SFEI in the “tables” folder) for each analysis type desired. Each table provides details of the regional/local dataset(s) being used in the specified analysis. For each analysis type selected, the user will determine which regional/local datasets should be included.
If including Location Analysis
- Open locations.csv in the “tables” folder.
- For each regional/local dataset to be included, use the locations.csv, Field Metadata to determine entries in each table field. An example of a completed locations.csv table is here: Example locations.csv.
- Save locations.csv.
If including Ownership Analysis
- Open ownership.csv in the “tables” folder.
- For each regional/local dataset to be included, use the ownership.csv, Field Metadata to determine entries in each table field. An example of a completed locations.csv table is here: Example ownership.csv.
- Save ownership.csv.
If including Opportunities and Constraints Analysis
- Open opportunities_and_constraints.csv in the “tables” folder.
- For each regional/local dataset to be included, use the opportunities_and_constraints.csv, Field Metadata to determine entries in each table field. An opportunities_and_constraints.csv table is here: Example opportunities_and_constraints.csv.
- Ranking process:
- To fill out the opportunities and constraints table, first you list all of the layers under layer name with it’s associated layer path, alias, query, and buffer size.
- Then you rank that layer as either a positive or negative factor for ranking a GI location. If it is negative, type “-1” under “rank” if positive then type “1”.
-
Next, you organize all layers into factors such as:local development considerationinstallation feasibilitycommunity needsfunding opportunitieswater quality, etc.(you can also make up your own factors and/or put all layers within one or two factors).
- Factor weight: Assign a weight to each factor such that the sum of all factor weights = 1 (for example, .25 for Local Development and .75 for installation feasibility if those were the only two factors you were using). A higher number indicates a higher weight for a particular factor. Provide this value to each layer row that the factor applies to.
- Layer weight: Within each factor, assign a weight to each layer so that the sum of the layer weights within each factor = 1. A higher number indicates a higher weight for a particular layer. If there is only one factor within that layer then the weight of that layer as 1.
- This table then runs nested weighted sums in order to produce a final ranking for each lid potential location. Note, you may choose to edit the opportunities and constraints table after viewing results. This is often an iterative process in order to create the most useful output for a user. Or you could purposely run it different ways for each neighborhood if there are specific local interests that are more or less important.
- Save ownership.csv.
If including Knockouts Analysis
- Open knockouts.csv in the “tables” folder.
- For each regional/local dataset to be included, use the knockouts.csv, Field Metadata table to determine entries in each table field. An example of a completed knockouts.csv table is here: Example knockouts.csv.
- Save knockouts.csv.
Preparing GI Size Table
SFEI has also provided lid_size.csv, which lists each GI type along with a suggested average area (square feet). When running the Site Locator Tool, the GI Size Table is used to remove GI locations that do not meet the minimum area specified. This table is also required if the user plans on running the Optimization Precursor Tool to generate inputs for the GreenPlan-IT Optimization Tool.
Use of the gi_size.csv table is optional, but recommended.
If including the GI Size Table…
- Open gi_size.csv in the “tables” folder.
- Adjust the values in the “ave_size_sqft” as desired/necessary. An example of a completed lid_size.csv table is here: Example gi_size.csv. See gi_size.csv, Field Metadata for field descriptions.
- Save gi_size.csv.
Loading the GreenPlan-IT Toolbox
- Open a new map document in ArcMap.
- If the ArcToolbox Window is not open, click the ArcToolbox button
 on the Standard Toolbar.
on the Standard Toolbar. - If the GreenPlan-IT Tool is not visible in the ArcToolbox Window…
- Right-click ArcToolbox.
- Select Add Toolbox…

- Browse to the location of the SiteLocatorTool_GreenPlanIT_SFEI folder, and select the GreenPlan-IT.pyt toolbox file.

- Click Open.
- The GreenPlan-IT Toolbox has now been added to the ArcToolbox Window.

1 - Site Locator Tool
The Site Locator Tool is the primary tool in GreenPlan-IT Toolbox. This tool identifies (and ranks, when Opportunities and Constraints Analysis is used) feasible locations for GI development.
Hardware/ ESRI Software Requirements
- 8 GB RAM (required); 16 GB RAM (recommended)
- 64-bit background geoprocessing
- Spatial Analyst Extension
Running the Tool
- Double-click 1 – Site Locator Tool in the GreenPlan-IT Toolbox.
- The tool will open to the following interface:

- Output Directory: Select the folder where you would like the site locator tool outputs to save. We recommend that the character length of the output directory be < 100 characters.
- Set the extent: You may set the extent by (a) selecting an Area of Interest or (b) setting a Custom Area of Interest using a polygon feature class with a single feature containing the desired boundary area.
- To select an Area of Interest: Use the Area of Interest dropdown menu and select the desired area.

- To select a Custom Area of Interest: Select "[Custom Area of Interest]" under the "Area of Interest" field. This activates the "Custom Area of Interest (optional)" field which you can then specify the polygon feature class containing your custom boundary.
- To select an Area of Interest: Use the Area of Interest dropdown menu and select the desired area.
- GI Types: Select at least one GI type to include in the Site Locator analysis.
- Modules (optional): Select the modules/additional analyses to be included when running the tool.
- Restrict Output to Base Analysis Extent: SFEI has provided a base analysis for each of the nine (9) GI types. Check to restrict the final outputs to only areas that overlap the regional suitability layer for each GI type.
- Note: The base analysis layers can be incorporated two ways: (1) Check “Restrict Output to Base Analysis Extent”to exclude all locations that are NOT identified as suitable area for each GI type in the base analysis. (2) Do not check “Restrict Output to Base Analysis Extent” to prevent results from being limited to locations identified as suitable for each GI type in the base analysis. You may still include the base analysis layer in the Opportunities and Constraints module and run the tool for that type of GI only, in order to rank locations that fall within the base analysis areas as higher. This second option may be the preferable method. See Preparing Analysis Tables.
- Module Tables (optional): Table paths should only be provided for selected modules/analyses.
- Locations Table: If you selected the Location Analysis module, navigate to and select your locations.csv table.
- Opportunities and Constraints Table (Default and GI specific): If you selected the Opportunities and Constraints Analysis module, navigate to and select your opportunities_and_constraints.csv table for each GI type.
- Note: you can specify a "Default" Opportunities and Constraints Table which will be used for any GI types that do not have a GI specific Opportunities and Constraints Table specified.
- Ownership Table: If you selected the Ownership Analysis module, navigate to and select your ownership.csv table.
- Knockout Table: If you selected the Knockout Analysis module, navigate to and select your knockouts.csv table.
- GI Size Table: If using average GI sizes in the Site Locator analysis, navigate to and select your gi_size.csv table.
- Export KMZ of Outputs: Check to generate KMZs of the GI locations; these may be viewed in Google Earth or Google Maps.
- Note: The KMZs generated by the GreenPlan-IT Site Locator Tool contain simplified feature polygons and should be used for general viewing purposes only. Any analysis should be performed using the feature classes in the file geodatabase.
- Save PNG of Outputs: Check to export a PNG map of the outputs. The legend provided with the tool will have to be added manually.
- Save PDF of Outputs: Check to export a PDF map of the outputs. The legend provided with the tool will have to be added manually.
- Click OK to run. (The tool may take several hours to run to completion, depending on the size of the area of interest, the number of GI types selected, and the number of modules included.)
Understanding the Outputs
Final File Geodatabase of Outputs
As the GreenPlan-IT Site Locator Tool runs, feature classes and table outputs will be saved in a file geodatabase in the Output Directory. Many of these are projected copies of the input data or intermediate analyses; however, the final GI locations for each selected GI Type will be saved in the following format:

Notes:
- A ranking will only be applied when the Opportunities and Constraints Analysis has been applied.
- Feature classes ending in “_private” or “_public” separate GI locations into the private and public domains, respectively. These feature classes are only generated if a distinction between private/public areas has been made in the Location Table and/or Ownership Table.
GI Location Feature Class Description
Each final GI location feature class will follow this field schema: Feature Class Metadata.
GI Area by Rank
For each GI type selected, the Site Locator Tool will generate a summary of GI areas (acres) by 0.1 rank intervals. These tables will have names according to the format, “GI_Area_by_Rank_GI Type_yyyy.mm.dd.csv”.
Unranked areas will be assigned rank = 9999.
KMZ Exports
If Export KMZ of Outputs was selected, a “KMZ_OUT_yyyy.mm.dd_hh.mm.ss” folder will be saved in the Output Directory. Each KMZ represents a geographic quadrant of the area of interest. A set of KMZ quadrants is made for each selected GI type (one set each for all locations, and private locations and public locations, where applicable).
For example, the KMZ exports for the Bioretention GI Type with Ownership Analysis (i.e. private/public distinction) and Opportunities and Constraints Analysis (i.e. ranked) would look like this:

Additionally, if ranked, LID location polygons are symbolized according to the following color scheme:

Unranked areas will be assigned rank = 9999.
Messages and Summaries
The GreenPlan-IT Tool auto-generates a message and summary file each time the Site Locator Tool is run:
GI_Site_Suitability_AreaOfInterest_yyyy.mm.dd_hh.mm.ss_messages.txt – this is a text record of input tool parameters and execution messages/errors.
GI_Site_Suitability_AreaOfInterest_yyyy.mm.dd_hh.mm.ss_summary.csv – this is a record of input tool parameters and completion times for any module analyses, as well as the total tool completion time.
2 – Optimization Precursor Tool
The Optimization Precursor Tool generates the required inputs for the GreenPlan-IT Optimization Tool. This tool calculates the total area of each GI type within each sub-basin (produced during hydrologic modeling of the area). Additionally, the Optimization Precursor Tool calculates the number of possible GI locations within each sub-basin based on the minimum GI areas defined in the GI Size Table.
Note: Where multiple GI locations overlap, the overlap area is divided amongst the relevant GI types. In this way, total area is conserved.
Running the Tool
- Double-click 2 – Optimization Precursor Tool in the GreenPlan-IT Tools toolbox.
- The tool will open to the following interface:

- Input Geodatabase: Select the file geodatabase generated from the Site Locator Tool. The name of this geodatabase will have a name similar to LID_Site_Suitability_AreaOfInterest_yyyy.mm.dd_hh.mm.ss.gdb.
- Output Directory: Select the folder where you would like the Optimization Precursor Tool outputs to save.
- Sub-basin Feature Class: Select a polygon feature class containing the sub-basin boundaries for the area of interest.
- Sub-basin ID: Use the dropdown menu to select a unique ID field from the Sub-basin Feature Class. If a unique ID field does not exist, use the Object ID field.
- GI Types: Select the GI types to include in the Site Locator analy.
- GI Size Table: Navigate to and select your lid_size.csv table.
- GI Size Table Unit: Select the unit of measure in the GI size table: (SQUARE) FEET or (SQUARE) METERS.
- Ownership Domains: Use the dropdown menu to select the ownership domain.

- Click OK to run.
Understanding the Outputs
The primary output of the Optimization Precursor Tool is the table “Sub-basin_Model_Input_yyyy.mm.dd_hh.mm.ss.csv”. This table summarizes the total area by GI type in each sub-basin; it also estimates the number of potential GI installations (by type) in each sub-basin, based on the total area and average GI sizes as specified in the GI Size Table.
Note: Where multiple GI locations overlap, the overlap area is divided amongst the relevant GI types. In this way, total area is conserved.
The specific fields/field names included in this table will vary based on the user inputs.
Modeling Tool
GreenPlan Modeling Tool User Guidance
Prepared by
SAN FRANCISCO ESTUARY INSTITUTE
4911 Central Avenue, Richmond, CA 94804
Phone: 510-746-7334 (SFEI)
Fax: 510-746-7300
Table of Contents
1. INTRODUCTION……..……………………………………………………………………...................1
2. DOWNLOAD AND SET UP SWMM. ……………………………………………………..............1
3. MODEL DEVELOPMENT………………………………………………………………….................2
3.1 Input data ..................................................................................................2
3.2 Watershed Delineation................................................................................3
3.3 Hydrology Calibration.................................................................................3
3.4 Water Quality Calibration............................................................................5
3.5 GI Simulation..............................................................................................6
4. MODEL LIMITATIONS……………………..……………………………………………...................6
5.REFERENCES....................................................................................................7
1. INTRODUCTION
The modeling tool of the GreenPlan-IT toolkit is a spatially distributed hydrologic and water quality model that simulates runoff quantity and quality from primarily urban areas as well as hydrologic performance of Green Infrastructure (GI). The tool is built upon the publicly available EPA Storm Water Management Model (SWMM) (Rossman, 2010), a dynamic rainfall-runoff simulation model used for single event or long-term (continuous) simulation of runoff quantity and quality and is used for planning, analysis and design related to stormwater runoff management, combined and sanitary sewers, and other drainage systems in urban areas. Within the toolkit, this tool is used to establish the baseline hydrology and water quality conditions through the characterization of the modeled watershed before any new management activities are implemented; identify high-yield runoff and pollution areas; and evaluate relative effectiveness of implementing GIs across different areas within a watershed, based on their potential for reducing runoff volume or contaminant loads.
The modeling tool currently utilizes three modules of SWMM: (1) the hydrological module; (2) the pollutant module; and (3) the GI module. The hydrologic and pollutant modules are used to simulate the generation, transport, and fate of stormwater runoff and associated pollutants from the landscape. The GI module utilizes stormwater runoff from the hydrologic module as the forcing function for GI simulation to estimate any reduction made from GI implementation by performing without and then with the GI scenarios simulation.
Since SWMM is an established public domain model, users of GreenPlan-IT can obtain existing SWMM documentation from the EPA SWMM website (briefly discussed in next section) for guidance on how to set up and run the model. As such, this manual will not provide a detailed description of SWMM, its strengths and weaknesses, or software and hardware requirements, nor step by step instructions on model setup as a regular user manual would do. Rather, it will focus on providing guidance on model development and application. Before running GreenPlan-IT, users should familiarize themselves with the SWMM user guidance.
The Green Plan-IT modeling tool is intended for knowledgeable users familiar with technical aspects of watershed modeling more generally and SWMM ideally.
2. DOWNLOAD AND SET UP SWMM
The SWMM installation program, user’s manual, as well as source code are available at the EPA SWMM website: http://www2.epa.gov/water-research/storm-water-management-model-swmm.
Users can follow the instructions provided at this link to download and install SWMM on a PC. In particular, users will need to download:
- Self-extracting installation program for SWMM5.0. Run this .exe file will install SWMM on a PC. The detailed instruction on model installation and pertinent software/hardware requirements are provided in the SWMM user manual.
- SWMM5.0 User’s Manual. This is the main SWMM document that provides step-by-step instructions on how to set up and get started with SWMM, as well as detailed description on SWMM structure and various functionalities and options (graphical user interface, the project files, and how to build a network model of a drainage system, use the study area map, run a simulation, and the various ways to view model results).
In addition, users are strongly encouraged to download and go through the ‘SWMM Applications Manual’ to help expedite their use of SWMM. It contains nine worked-out examples that illustrate how to use SWMM to model some of the most common types of stormwater management and design problems. In some cases, advanced users may also want to download and manipulate the SWMM source code to meet their specific needs.
3. MODEL DEVELOPMENT
The model development for a SWMM application is similar to most watershed modeling projects and usually begins with collecting and reviewing input data, followed by setting up the model, and calibrating the model to match local data. Once the model development is completed, the model can then be used to answer management questions by simulating various management scenarios. In the case of this project, the developed modeling tool is used to drive GI simulation.
3.1 Input Data
The development of a hydrologic model requires all water sources and sinks to be included in the model. The data collection process involves a thorough compilation and review of information available for the study area. It generally includes gathering applicable regional and site-scale GIS data layers, digital elevation model (DEM) data, stream networks, soil, land use, critical source information, and monitoring data for calibration and validation. A summary of typical data needs for SWMM development is provided in Table 3-1.

3.2 Watershed Delineation
Watershed delineation is a process that divides a watershed into smaller sub-basins to analyze watershed behavior. Consistent with the lumped nature of the model, each sub-basin is modeled as a homogeneous unit with spatially averaged descriptive properties. Watershed delineation is normally done by GIS analysis using topographical data. The watershed delineation will establish a representation of the study area, and ideally, locally derived higher-resolution site scale data should be used. The proper spatial scale of a modeling project is usually determined through professional judgment and needs to take into account important factors such as the project goals, size of the study area, spatial scale of crucial input data, and model run time. For a stormwater management project, watershed delineation should strike a balance between a meaningful size of sub-basins for guiding GI implementation and demand on computer run time.
3.3 Hydrology Calibration
Similar to other modeling efforts, a critical first step for SWMM development is to calibrate the model using local data, before it is used by municipalities to simulate GI scenarios for their local watersheds. A hydrologic calibration is typically done by means of an iterative process of trial and error, by adjusting the parameters within the established range until modeled flow rates match the timing, magnitude, and total volume of the field-observed streamflow data. The model calibration is necessary to ensure that a representative baseline condition is established with a high degree of confidence in its applicability to form the basis for comparative assessment of various management scenarios.
SWMM is associated with a large number of spatially variable parameters that describe the characteristics of individual sub-basins. A subset of the model parameters associated with frequent storm events (impervious percentage, subcatchment width, Manning’s roughness, depression storage, and soil infiltration parameters) are most sensitive and typically used as hydrologic calibration parameters. A brief discussion of each parameter follows.
- Imperviousness
The percentage of impervious area is often the most sensitive parameter, strongly influencing both total runoff volume and peak flows. The initial estimate of imperviousness is usually determined by GIS analysis of land use/land cover data. During calibration, the percent¬age of imperviousness is adjusted up/ down as necessary to be consistent with known conditions in the study area and to obtain a good adjustment of the hydrograph.
- Subcatchment width
The subcatchment width is computed by dividing the subcatchment area by the travel length. This is an abstract basin parameter and is commonly used as a “tuning parameter” for model calibration because of the uncertainty associated with determining the travel length of stormwater runoff. Increasing the travel length decreases the subcatchment width which creates a more attenuated response to storm events.
- Manning’s (surface) roughness
Manning’s roughness coefficient is used in SWMM for the routing of overland flows and has an influence on the timing of peak flows. Separate roughness coefficients are applied to pervious versus impervious surfaces. Typical values are as follows:
- Impervious: 0.015 (dimensionless)
- Pervious: 0.250 (dimensionless) or higher in heavily vegetated areas
Manning’s n values are often assigned a default value (from typical value suggested in SWMM User Manual, GIS analysis of land cover type and/or literature review), and then adjusted within the range of the established values in the literature to ensure they are representative of current basin conditions.
- Depression storage
Depression storage refers to the storage depth associated with surface depressions that are filled prior to runoff. The potential depression storage is related to the surface roughness coefficient; thus, separate values are required for pervious and impervious surfaces. Typical values are as follows:
- Impervious: 0.1 inch
- Pervious: 0.2 inch
Depression storage affects sensitivity of runoff to precipitation and is negatively and weakly correlated to surface runoff. Adjusting this parameter could improve model performance, but the improvement is often limited.
- Soil infiltration parameters
SWMM offers three choices for modeling infiltration: the Horton's Equation, the Green-Ampt Method, and the Curve Number Method, each requiring a different set of input parameters. Regardless of the method used, the infiltration parameters are closely correlated to hydrologic characteristics of the soil groups. Regional data available from the NRCS in the State Soil Geographic Database (STATSGO) is commonly used in lieu of local soil information to determine the default values and allowable ranges for each parameter. The calibration process then involves varying the parameters within their defined bounds in an effort to optimize the model.
Other less sensitive parameters required by SWMM such as subcatchment slope and percent of impervious area with no depression storage can be assigned a default value based on recommendation from the SWMM User Manual, GIS analysis and/or literature review.
3.4 Water Quality Calibration
SWMM can simulate the production of pollutant concentrations and loads associated with stormwater runoff. The model is capable of analyzing the buildup, washoff, transport and treatment of a variety of water quality constituents such as sediment, heavy metals, and nutrient. Because the SWMM uses the buildup-washoff formulation that assumes urban runoff quality constituents behaving in some manner similar to “sediment” of sediment transport theory, it works well for constituents that are transported in solid form, either as particulates or by adsorption onto soil particles, but not for constituents that are transported primarily in a dissolved state, e.g., NO3. Water quality parameters are defined for buildup and washoff of each pollutant and include maximum surface build-up, surface build-up rate and wash-off coefficients. These parameters are land use specific and are primary parameters used for water quality calibration.
The water quality calibration is also made by means of an iterative process of trial and error, by adjusting the parameters within the established range, and comparing (numerically and graphically) the modeled results (usually pollutant concentrations) with the measured data, until a good fit is obtained. The water quality calibration has often proved more difficult than the hydrology calibration, due largely to the lack of high resolution calibration data, both temporally and spatially. Therefore, the calibration procedure should also incorporate the comparison of the outcomes with a reasonable conceptual understanding of the likely variation of pollutant sources, erosion, and transport processes in the landscape that is water quality parameter specific. The outcome of the water quality simulation should at least compare closely with this conceptual model and follow the reasonable likelihood that pollutant production should vary more between each sub-basin than flow production. For example, flow production between sub-basins normally varies by 2-4-fold between the least to the most imperious sub-basins whereas it is not uncommon for pollutant loads to vary by any magnitude between sub-basins by 5-100-fold.
3.5 GI Simulation
SWMM can simulate the hydrologic performance of seven GI types: Permeable Pavement, Rain gardens, Green roofs, Street planters, Rain barrels, Infiltration trenches, and Vegetative swales (Rossman, 2010). The GI simulation is usually performed after SWMM is developed for a watershed using local data, to quantify any runoff reduction associated with GI implementation.
For SWMM to simulate a GI, users need to specify GI design, location, and treatment area within a watershed. The types of GI compartments are: storage, underdrain, surface, pavement and soil. GI controls are represented by a combination of these vertical layers whose properties are defined on a per-unit-area basis. These compartments are GI specific and the SWMM5 user manual (Rossman, 2010) provides a detailed description on the configuration of each GI type.
4. MODEL LIMITATIONS
Despite its capacities for addressing many stormwater problems, SWMM has a number of limitations that users need to be cognizant of before using the model.
- Although it has been widely used elsewhere, the model is not directly applicable to large-scale, non-urban watersheds, and performs best in urbanized areas with mainly impervious cover within drainage area of interest.
- The model is not applicable to forested areas or irrigated cropland because of lack of parameterization for evapotranspiration in the model.
- Water quality simulations follows a simple buildup-washoff process, as such, the model is best suitable for modeling pollutants in particle form or closely associated with sediment, and less applicable to pollutants in dissolved forms (i.e. nitrogen species).
- The model only computes sediment delivery from overland flow. The model does not contain mechanisms for sediment deposition and transport within a river channel.
- The model is currently only capable of simulating hydrologic performance of selected GI types. The mechanistic simulation of pollution reduction is not built into the model. Additional programing by the user is required for simulating load reduction within the GI types.
5. REFERENCES
Rossman, L. A (2010). Storm Water Management Model User’s Manual, Version 5.0, U.S. Environmental Protection Agency. Office of Research and Development. EPA/600/R-05/040.
USEPA (2011). Report on Enhanced Framework (SUSTAIN) and Field Applications for Placement of BMPs in Urban Watersheds, EPA 600/R-11/144. U.S. Environmental Protection Agency, Office of Research and Development, Cincinnati, OH.
Optimization Tool
![]() Optimization Tool User Manual 2020.pdf
Optimization Tool User Manual 2020.pdf
Optimization Tool User Manual
Prepared by
SAN FRANCISCO ESTUARY INSTITUTE
4911 Central Avenue, Richmond, CA 94804
Phone: 510-746-7334 (SFEI)
Fax: 510-746-7300
July 2020
Table of Contents
1. OVERVIEW
1.1 GreenPlan-IT
1.2 Optimization Tool Overview
1.3 Optimization Algorithm
1.4 Structure of Optimization Tool
2. FORMULATION OF OPTIMIZATION
3. INSTALL OPTIMIZATION TOOL
4. RUN OPTIMIZATION TOOL
4.1 Create Input Files
4.2 Run the Tool
5. REVIEW AND INTEPERATE OUTPUTS
6. FUTURE UPGRADES
7. REFERENCES
OVERVIEW
1.1 GreenPlan-IT
GreenPlan-IT is a planning tool that was developed over the past five years with strong Bay Area stakeholder consultation. GreenPlan-IT was designed to support the cost-effective selection and placement of Green Infrastructure (GI) in urban watersheds through a combination of GIS analysis, watershed modeling and optimization techniques. GreenPlan-IT comprises four distinct tools: (a) a GIS-based Site Locator Tool (SLT) that combines the physical properties of different GI types with local and regional GIS information to identify and rank potential GI locations; (b) a Modeling Tool that is built on the US Environmental Protection Agency’s SWMM5 (Rossman, 2010) to establish baseline conditions and quantify anticipated runoff and pollutant load reductions from GI sites; (c) an Optimization Tool that uses a cost-benefit analysis to identify the best combinations of GI types and number of sites within a study area for achieving flow and/or load reduction goals; and (d) a tracker tool that tracks GI implementation and reports the cumulative programmatic outcomes for regulatory compliance and other communication needs. The GreenPlan-IT package, consisting of the software, companion user manuals, and demonstration report, is available on the GreenPlan-IT web site hosted by SFEI (http://greenplanit.sfei.org/).
1.2 Optimization Tool Overview
The optimization tool of GreenPlan-IT can be used to identify and prioritize the most cost-effective GI implementation among the many options available in urban and developing areas. The tool uses an evolutionary optimization technique, Non-dominated Sorting Genetic Algorithm II (NSGA-II), to systematically evaluate the benefits (runoff and pollutant load reductions) and costs associated with various GI implementation scenarios (location, number, type, and size of GI) and identify the most cost-effective options for achieving desired flow mitigation and pollutant reduction at minimum cost. Figure 1-1 shows an example GI scenario that specifies types and numbers of GI features within different sub-basins (locations). Within GreenPlan-IT, the optimization tool is structurally designed as a standalone module to provide flexibility for the user community, but it needs interaction with other tool components to function. The optimization tool uses the site information generated from the GIS Site Locator tool as input data and interacts with the modeling tool during the search process in an iterative and evolutionary fashion to generate viable GI scenarios and compare their performance. Therefore, running the tool requires the running of both the Site Locator Tool and Modeling Tool (http://greenplanit.sfei.org/).
The optimization tool is designed to help local watershed planning agencies to develop stormwater management plans and coordinate watershed-scale investments to meet their program needs. It is intended for knowledgeable users familiar with the physics of GI and the technical aspects of watershed modeling. The tool outputs, combined with other site specific information.
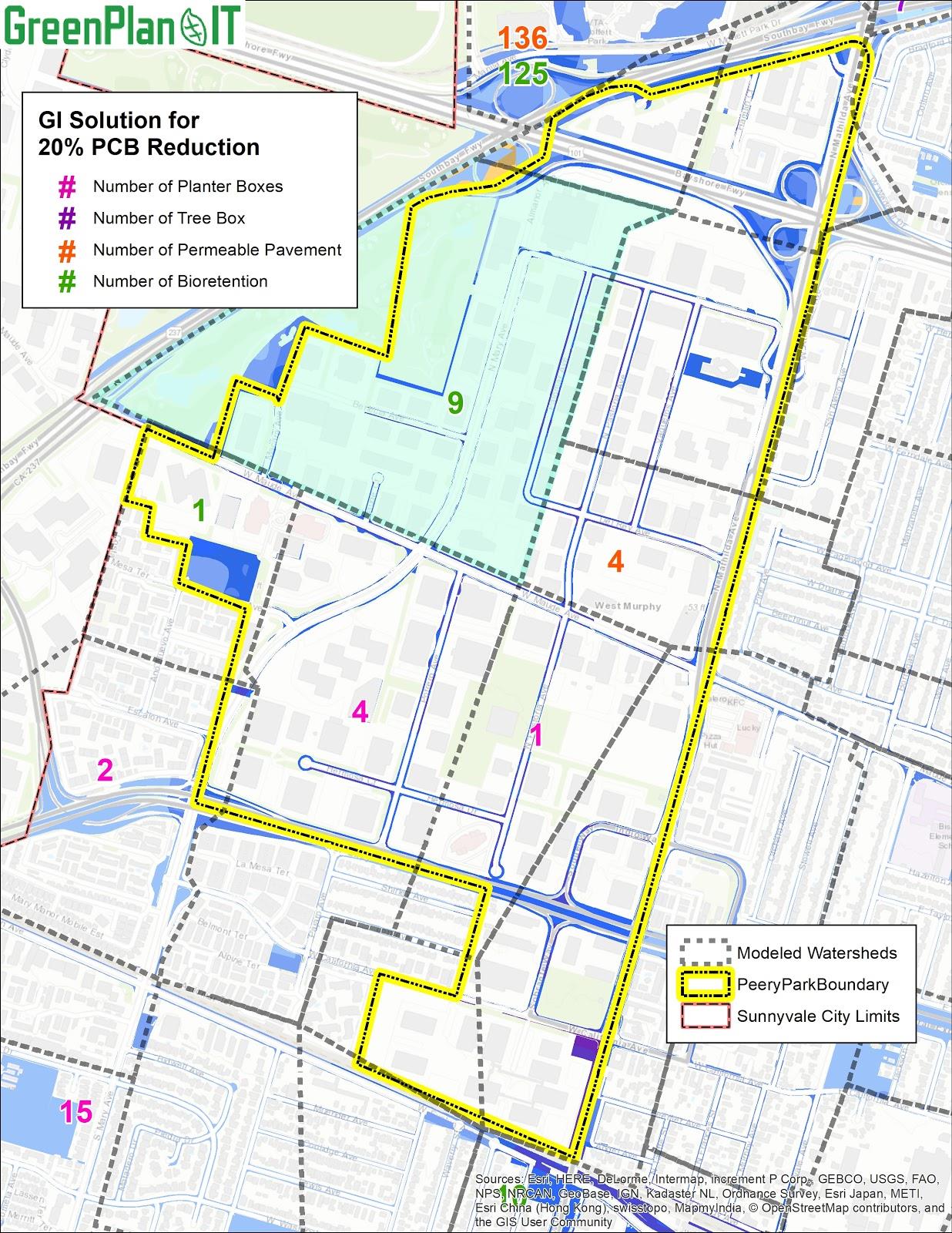
Figure 1-1. Example GI scenario showing types and numbers of GI features (color coded, see map legend) within different sub-basins (locations)and management requirements, can be used to develop watershed-scale Green Infrastructure master plans.
1.3 Optimization Algorithm
Belonging to the family of evolutionary optimization techniques, NSGA-II is one of the most efficient and widely used multi-objective optimization algorithms that is capable of producing optimal or near-optimal solutions that describe tradeoffs among competing objectives (Deb, et al, 2002). NSGA-II incorporates a non-dominating sorting approach that makes it faster than any other multi-objective algorithm and uses a crowded comparison operator to maintain diversity along the Pareto optimal front (Srinivas and Deb, 1994). Examples of the use of NSGA-II for addressing environmental problems have been reported in the EPA SUSTAIN applications (USEPA 2009) as well as many case studies in the literature (Bekele and Nicklow, 2007; Bekele, et al, 2011; Maringanti, et al, 2008; Rodriguez, et al, 2011). The major operation steps of NSGA-II are described below.
-
Creation of First Generation
The algorithm begins with random generation of an initial population of potential solutions. The population is sorted based on the concept of Pareto dominance (non-domination) into each front. A solution is non-dominant to another solution when itperforms no worse than the other solution in all objectives, and better than the other solution in at least one objective. At the end of the sorting, each solution is assigned a fitness (or rank) equal to its non-dominant level, with a smaller rank indicating that the solution is dominated by fewer other solutions. In addition, a crowding distance, defined as the size of the largest cuboid enclosing a solution without including any other solution in the population, is calculated for each individual solution as a measure to maintain solution diversity. Large average crowding distance results in better diversity in the population.
-
Optimization Process
In the first step of the optimization process, parent populations are selected from the population by using binary tournament selection based on the rank and crowding distance. An individual solution is selected if the rank is lesser than the other solutions or if crowding distance is greater than the other solutions. The selected population generates an offspring population of the same size from the processes of crossover and mutation. The combined population of the current parent and offspring is sorted again according to non-domination and only the best N individuals are selected to form a new parent population, where N is the population size. Elitism is ensured in this step because both the parent and the child populations are used in the sorting. Comparison of the current population with previously identified non-dominated solutions are performed at each iteration. The new parent population is then used to create a new child population, and the process continues until the stopping criteria are met. At that point, the optimization is considered converged at an optimal front and the process can be stopped.
-
Stop Criteria
The users can stop the NSGA-II using some user-defined stop criteria. The commonly used criteria include maximum number of iterations; no change in the new parent population for two consecutive loops; and no tangible improvement for the fitness function after a certain number of iterations.
1.4 Structure of Optimization Tool
Structurally, the optimization tool is built around three functionalities each supported by a group of subroutines: Optimizer, GI performance evaluator, and cost calculator. The optimizer serves as the optimization engine that generates GI scenarios and drives the search process through the NSGA-II algorithm. The GI performance evaluator is used to create input files for the modeling tool to incorporate the generated GI scenarios, runs the model with new input files, and passes GI performance data generated by the model back into the optimizer. The cost calculator is used to estimate the cost of each GI scenario and to pass that information into the optimizer.
The three function groups work hand-in-hand in an iterative and evolutionary fashion to search forthe best GI solutions that meet the user’s specific conditions and objectives. During the search process, new GI scenarios are generated through the optimizer within the search space defined by the universe of feasible locations that are identified by the GIS Site Locator tool, the GI performance for each of the scenarios are evaluated, and costs for each are estimated. The optimizer then systematically compares the cost and performance data and modifies the search path to generate a new set of viable GI options and repeats the process until the set criteria to end the iteration are reached. Figure 1-2 presents a conceptual overview of the tool.
The optimization tool was written in FORTRAN language. The coding of NSGA-II was verified with example problems provided at Deb, et al (2002) to make sure the optimization algorithm was implemented correctly. The maximum number of iterations was used as stop criteria.
2. FORMULATION OF OPTIMIZATION
The formulation of the multi-objective optimization problem involves defining optimization objectives, determining decision variables, and identifying associated constraints.
-
Optimization Objectives
The optimization objectives used in this tool are to: 1) minimize the total relative cost of GI scenarios; and 2) maximize the total PCBs load reduction within a study area.
-
GI Types and Design Specifications
Four GI types - bioretention, permeable pavement, tree well (proprietary media), and flow-through planter, are currently included in the Optimization Tool, but other types could be added by an advanced user. Each GI type is assigned typical size and design configurations that were reviewed and approved by the Technical Advisory Committee (TAC) (Table 2-1). These design specifications remain unchanged during the optimization process. But if a user wants to use different design specifications for these four types, or have four totally different GI types to fit their specific needs, this can be easily achieved by changing the GI attributes in both the SWMM template file and the LID input file for optimization (discussed in Section 3).
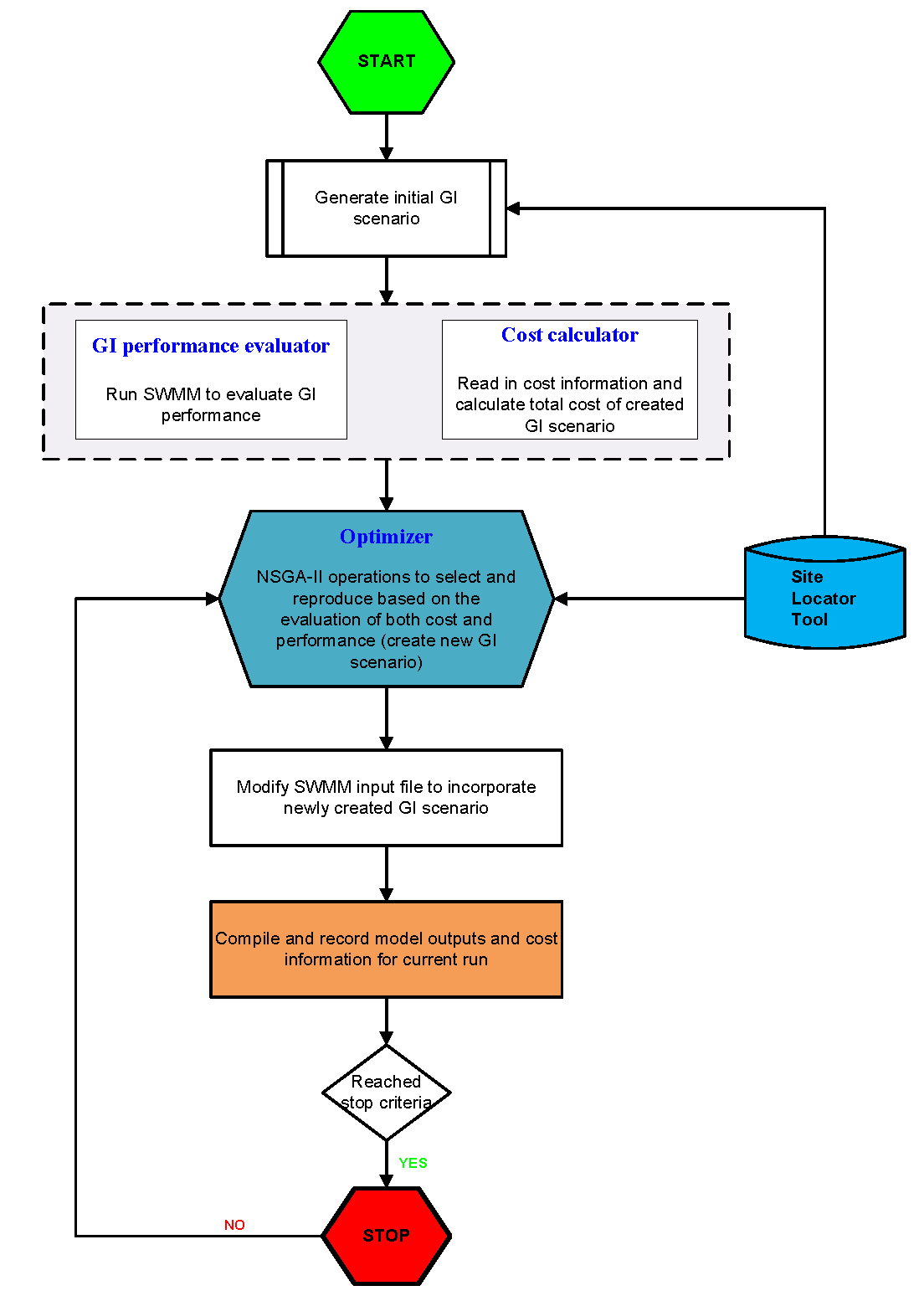
Figure 1-2. Flowchart of Optimization Tool
While current template files for the tool only include four GI types, the tool is set up to take up to six GI types. If a user is interested in other GI types, they can specify them in both the SWMM file and optimization input file, but including more than six GI types will require minor changes and recompilation of source code.
Table 2-1. GI types and configurations currently used in the Optimization Tool.
|
GI Specification |
Surface area (sf) |
Surface depth (in) |
Soil media depth (in) |
Storage depth (in) |
Infiltration rate (in/hr) |
Underdrain |
Sizing factor* |
Area treated (ac) |
|
Bioretention |
500 (25x20) |
9 |
18 |
12 |
5 |
Yes: Underdrain at drainage layer |
4% |
0.29 |
|
Permeable pavement |
5000 (100x50) |
0 |
24 |
100 |
Yes: 8 inch for underdrain |
50% |
0.23 |
|
|
Tree well |
60 (10x6) |
12 |
21 |
6 |
50 |
Yes: Underdrain at bottom |
0.4% |
0.34 |
|
Flow-through planter |
300 (60x5) |
9 |
18 |
12 |
5 |
Yes: Underdrain at bottom |
4% |
0.17 |
* In relation to the drainage management area of the unit.
-
Decision Variables
In the optimization, since GI design specifications were user specified and remained constant, the decision variables were therefore the number of units of each of the GI types in each of the subbasins within a study area. For each applicable GI type, the decision variable values range from zero to a maximum number of potential sites as specified by the boundary conditions identified by the GIS SLT.
-
Constraints on GI Locations
For each GI type, the number of possible sites is constrained by the maximum number of potential sites identified by the GIS locator tool. The decision variables were also constrained by the total area that can be treated by GI within each subbasin. Through discussion with the TAC, a sizing factor (defined as the ratio between GI surface area and its drainage area) for each GI type was specified and used to calculate the drainage area for each GI and also the total treated area for each scenario (Table 1-1). During the optimization process, the number of GI units is adjusted down when their combined treatment areas exceed the available area for treatment within each subbasin.
-
Stop Criteria Used
The maximum number of iterations is used as the stop criteria for the tool. The total number of iterative runs needed for the optimization process to converge to the optimal solutions is dependent on the number of decision variables, model simulation period, and the complexity of the model (number of sub-basins and stream network). For the current setup, 200 iterations were deemed sufficient after several test runs with different numbers. This number can be changed or different stop criteria can be used if so desired, but doing so will require modification of source codes and a thorough understanding of the optimization algorithm and consideration of computation time. Depending on the formulation of optimization problem, the optimization process could take a few hours to several weeks, and more iterations leads to longer computation time. In general, the computational efficiency can be achieved through reducing the number of decision variables, simulation time, and complexity of the problem.
3. INSTALL OPTIMIZATION TOOL
The optimization tool is designed to run under the Windows 2003/2013/NT/XP/Vista/7/10 operating system of a typical personal computer. To install the optimization tool and get ready to use it on your PC, follow the steps below:
-
Check that your Windows PC meets the system requirements.
-
Create project directory/folders to store the tool and input/output files. The main project folder can be under any root directory with any user-defined name. An example might be: “c:\My Folders\Optimization\”. Within the main folder, create three sub-folders as:
.\Binary.\Input.\Output
-
Download the tool package from GreenPlan-IT website: http://greenplanit.sfei.org/books/toolkit-downloads. Save the executable in the Binary folder and example input files in the Input folder.
-
Save SWMM5.exe in the Output folder.
4. RUN OPTIMIZATION TOOL
The optimization tool, as it currently stands, can be run as a console application from the command line within a DOS window. The steps of running the tool are as follows:
4.1 Create Input Files
Three input files are required to run the optimization tool. Each file needs to be created according to the specific format provided by the template files. All of them should be stored in the folder. \Input.
-
Basin_info.csv. This file contains total acreage and percent impervious of each sub-basin, as well as maximum number of feasible sites for each GI type within each sub-basin. The maximum number of possible GI sites are identified by the GIS Site Locator Tool and used as a constraint to the optimization.
-
LID_info.csv. This file contains three GI configuration parameters - surface area, surface width, and % of initial media saturation, and also sizing factor and unit cost for each GI type. Any of them in this file can be changed and customized to reflect local design and cost. The rest of GI configuration parameters are specified in the SWMM input file.
- SWMM_input.inp. During the optimization process, the Optimization Tool calls the Modeling Tool (SWMM5) to evaluate each GI scenario against the baseline condition. A SWMM input file needs to be created as the base for the model run, using the Windows version of SWMM5 for its easy-to use interfaces and many features. The majority of GI configuration parameters listed in Table 1-1 also need to be specified in this file (LID_CONTROLS section).
4.2 Run the Tool
Currently, the tool is set up to run in Windows command prompt:
1. Open a command prompt window;
2. Enter the path of the Optimization tool (Optim.exe), then add the path of project directory (the folder containing ‘Input’ and ’Output’ subfolders) after a SPACE.

3. Press ‘ENTER’ and run the tool.
At current setup, user only needs to specify the project folder that contains input/output folders to run the tool. Users can define their own project folder. Two caveats need to pay attention:
1. The structure of the project folder and the names of related files should follow the example below:

2. It is recommended to avoid space in the paths of the optimal tool and project folder. If there are space existing in the path, quote each path with quotation marks and then run the tool.
The key NSGA-II parameters are hardcoded, with number of generation = 200, population size =100, crossover probability=0.9 and mutation probability =0.1. The next phase of tool development will strive to make the tool more flexible to allow users to determine key NSGA-II parameters such as the number of iteration and population size.
5. REVIEW AND INTEPERATE OUTPUTS
The optimization tool produces a text file that contains reduction and cost information for all solutions and also saves SWMM input files for all intermediate solutions. All of these files are stored in the folder ./Output. The number of intermediate SWMM files can be in the order of tens of thousands, and thus, large hardware space is needed to store these files.
-
cost_reduction.txt. This is the main output file that contains generation#, population# within each generation, cost, and runoff volume reduction and percentage. Users can grab the information here to make the cost-reduction curve using Excel or other software. The reduction information in this file is needed to help you identify the optimal solution associated with specific reduction goal. For example, if a 30% reduction is desired, users can go to the file and find the generation # and population# with reduction closest to 30%. The optimal solution can then be extracted from the SWMM input file with the identified generation # and population#.
-
SWMM files for baseline. The SWMM files for baseline condition is created at the beginning of the optimization process to serve as the basis for comparison of various GI scenarios. This is done by removing any GI types in [LID_USAGE] section in the input file (.inp). The resulted report file (.rpt) after SWMM run provides baseline runoff and loads that are used as the basis to calculate their percent removal. Therefore, these files should be kept in place as removing them will crush the tool.
-
SWMM input files. The SWMM input file (.inp) for each generated GI scenario was saved to keep a record of the optimization process, and most importantly to track the optimal combinations of GI number and types. The files are named as SWMM_input_g#_p#, where g represents generation, p as population and # as the number of generation and population. For example, SWMM_iput_g002_p080.inp represents SWMM input file for generation 2 and population 80. Once users identify the targeted file, they can click open the file and mine the optimal LID solutions from the [LID_USAGE] section. For the current setup, about 40,000 files are generated that requires 10~15GB of storage.
By design, the SWMM output files are not saved in order to avoidcreating too many files that would take up a lot of computer storage space. If a user is interested in reviewing the model results from any scenarios created during optimization, one can simply run SWMM with the model input file for that particular scenario, and review model report file (.rpt) for runoff, pollutants, and GI performance information for the entire basin as well as each individual sub-basins.
It is important to emphasize that users must interpret the optimization results in the context of specific problem formulations, assumptions, constraints, and optimization goals unique to their study. If one or more assumptions are changed, the optimization might have resulted in a completely different set of solutions in terms of GI selection, distribution, and cost. It also should be noted that because of the large variation and uncertainty associated with unit GI cost information, the total cost associated with various reduction goals calculated form the unit cost do not necessarily represent the true cost of an optimum solution for the basin evaluated and are not transferable to other basins. Rather, these costs should be interpreted as a common basis to evaluate and compare the relative performance of different GI scenarios. The optimization tool provides a framework to identify optimal solutions for addressing stormwater management issues at a watershed level. Its application must be preceded by an intimate understanding of the study area and the influential factors affecting stormwater of the study area.
6. FUTURE UPGRADES
To ensure the optimization tool is comprehensive and flexible enough to handle a variety of situations/questions, the tool needs to be continuously evolving. Possible future enhancements to the optimization tool include:
- More flexibility
At current setup, the input file names/paths and many important decision variables such as the total number of iterative runs and the size of population were predetermined and hardcoded to expedite the tool development. The next phase of the tool development could make key decision variables of an optimization problem as user-defined inputs to provide flexibility for broad applicability. Also, the tool is currently tailored toward stormwater volume and pollutant load reduction, future upgrades are needed to enable the tool to handle a variety of management targets on both water quantity and quality.
- More GI types
Four GI types are included in the optimization tool at present stage that are accepted by Bay Area’s stormwater permits and recommended by municipalities and the TAC, and up to six can be customized by users. As a next step in development, more GI types as well as centralized regional facilities such as enlarged bioretention may be included in the mix to develop a diverse set of management options for a wide range of stormwater management problems.
7. REFERENCES
Bekele, E. G. and Nicklow, J. W. (2007). Multi-objective automatic calibration of SWAT using NSGA-II, Journal of Hydrology, 341, 165– 176.
Bekele, E. G., Lian, Y. and Demissie, M. (2011). Development and Application of Coupled Optimization-Watershed Models for Selection and Placement of Best Management Practices in the Mackinaw River Watershed, Illinois State Water Survey, Institute of Natural Resource Sustainability, University of Illinois at Urbana-Champaign.
Deb, K., Pratap, A., Agarwal, S., and Meyarivan, T. (2002). A fast and elitist multiobjective genetic algorithm: NSGA-II, IEEE Transactions on Evolutionary Computation, 6(2) (2002) 182-197.
Maringanti, C., Chaubey, I., Arabi, M. and Engel, B. (2008). A multi-objective optimization tool for the selection and placement of BMPs for pesticide control, Hydrol. Earth Syst. Sci. Discuss., 5, 1821–1862.
Rodriguez, H. G., Popp, J., Maringanti, C., and Chaubey, I. (2011). Selection and placement of best management practices used to reduce water quality degradation in Lincoln Lake watershed, Water Resources Research, Vol. 47, W01507, doi:10 1029/2009WR008549.
Rossman, L. A (2010). Storm Water Management Model User’s Manual, Version 5.0, U.S.
Environmental Protection Agency. Office of Research and Development. EPA/600/R-05/040.
Srinivas, N. and Deb, K. (1994). Multiobjective Optimization Using Nondominated Sorting in Genetic Algorithms. Evolutionary Computation, 2(3):221 - 248.
USEPA (2009), SUSTAIN - A Framework for Placement of Best ManagementPractices in Urban Watersheds to Protect Water Quality, EPA/600/R-09/095.
USEPA (2011), Report on Enhanced Framework (SUSTAIN) and Field Applications for Placement of BMPs in Urban Watersheds, EPA 600/R-11/144.
GreenPlan-IT Tracker

Technical Memo
06.14.2018
Prepared by Tony Hale, PhD
San Francisco Estuary Institute
4911 Central Ave.
Richmond, CA 94804
Table of Contents
About the GreenPlan-IT Toolkit
The Purpose of the GreenPlan-IT Tracker
Intended Audience for this Document
Figure 1 : The Richmond Waterfront and associated green infrastructure.
Detailed Information on a per-site basis
Figure 2: Detailed Information on facilities.
Figure 3: Detailed geospatial designation of drainage management areas and treatment areas.
Reporting information for inclusion in stormwater reports
Figure 4: Information suitable for inclusion in stormwater reports.
“Effectiveness reporting” for individual installations
Figure 5: Effectiveness Reporting by individual facility.
“Effectiveness reporting” for the municipal green infrastructure portfolio
Figure 6: Effectiveness Reporting by jurisdiction.
Mapping of sites for external use
Figure 7: Embeddable map of the City of Richmond.
Figure 8: List of sites with link to export data.
Mobile-enabled entry and editing
Figure 9: Mobile view of Maintenance and Inspection Logs
Figure 10: Servers in a data center
Project: Healthy Watersheds, Resilient Baylands
Figure 11: Conceptual ERD for GreenPlan-IT Tracker.
Effectiveness Reporting Submodule
Summary of effectiveness reporting processing
Effectiveness Reporting Submodule
List of Figures
Figure 1: The Richmond Waterfront and associated green infrastructure
Figure 2: Detailed Information on facilities
Figure 3: Detailed geospatial designation of drainage management areas and treatment areas
Figure 4: Information suitable for inclusion in stormwater reports
Figure 5: Effectiveness Reporting by individual facility
Figure 6: Effectiveness Reporting by jurisdiction
Figure 7: Embeddable map of the City of Richmond
Figure 8: List of sites with link to export data
Figure 9: Mobile view of Maintenance and Inspection Logs
Figure 10: Servers in a data center
Figure 11: Conceptual ERD for GreenPlan-IT Tracker
Overview
This technical memo describes the purpose, functions, and structure associated with the newest addition to the GreenPlan-IT Toolset, the GreenPlan-IT Tracker. It also shares the opportunities for further enhancement and how the tool can operate in concert with existing resources. Furthermore, this memo describes a licensing plan that would permit municipalities to use the tool in an ongoing way that scales to their needs. The memo concludes with a provisional roadmap for the development of future features and technical details describing the tool’s platform and data structures.
About the GreenPlan-IT Toolkit
Municipalities across the state and beyond are carefully planning and implementing green infrastructure in their developed landscape to restore key aspects of the natural water cycle. Green infrastructure helps to achieve stormwater attenuation and contaminant filtration by increasing the pervious surfaces in often sophisticated ways. Additionally, green infrastructure features, as city dwellers have come to realize, demonstrate multiple benefits in addition to improving surface porosity, such as peak, volume, and load reductions, urban heat island mitigation, traffic calming, carbon sequestration, wildlife habitat, natural aesthetics, and others. The benefits are substantial, but so are the potential costs. GreenPlan-IT helps planners to make smart decisions in the types and locations of green infrastructure, minimizing effort and cost while maximizing the effectiveness of the public and private investments.
GreenPlan-IT modules are focused on green infrastructure planning and assessment, including the Site Locator Tool, Modeler, and Optimizer tools. Together the modular toolkit can be used to take a city from a position of not knowing where to consider GI placement (a daunting position given the MRP C3 and C11/12 requirements), to a plan that includes a list and map of feasible locations and a map of baseline flow and pollutant load conditions, and a selected optimal set of placement locations for achieving flow and load reductions at minimal cost. Now, with the advent of the GreenPlan-IT Tracker, there is also a web based tracker for quantifying and communicating the locations, types, and treatment areas of GI installations (the outputs of all the planning efforts) and quantifying the peak flows, volumes, and loads reduced (the outcomes of all the implementation and cost expenditure that the community is asking for).
The Purpose of the GreenPlan-IT Tracker
GreenPlan-IT Tracker complements the other components of the GreenPlan-IT toolset, a modular resource for municipalities seeking to plan for, optimize, and track their Green Infrastructure (GI). Unlike the other modules, however, the new GreenPlan-IT Tracker attends to the already-installed features, rather than prospective and planning-level work associated with Green Infrastructure. Accordingly, the Tracker tool handles the accounting of GI across the landscape, recording the characteristics of those installations, the geospatial details, and calculating the effect of those features on stormwater flow attenuation and filtration.
Value Proposition
Why would people use GreenPlan-IT Tracker? The tool is designed to track locations, treated pollutant mass, maintenance needs, and report spatial and cumulative outcomes of GI implementation for annual reports over years and decades. Rather than recording this information in a general purpose geodatabase -- as is the current convention among most Bay Area cities -- this tool saves its users time while also offering deeper insight into the locations, specifications, and effectiveness of their ever-growing portfolio of green infrastructure. Because it was developed using a highly versatile and flexible interface, the tool can be tailored to meet the needs of individual cities while also leveraging features common to all. It is easy to use and provides ready export capability so that users can readily take their data to go whenever they’d like.
Intended Audience for this Document
This document addresses topics designed for municipal staff, stormwater program leads, NGO representatives responsible for stewarding green infrastructure, and technical experts who are interested in learning about the suitability of the tool and applying it to meet their needs.
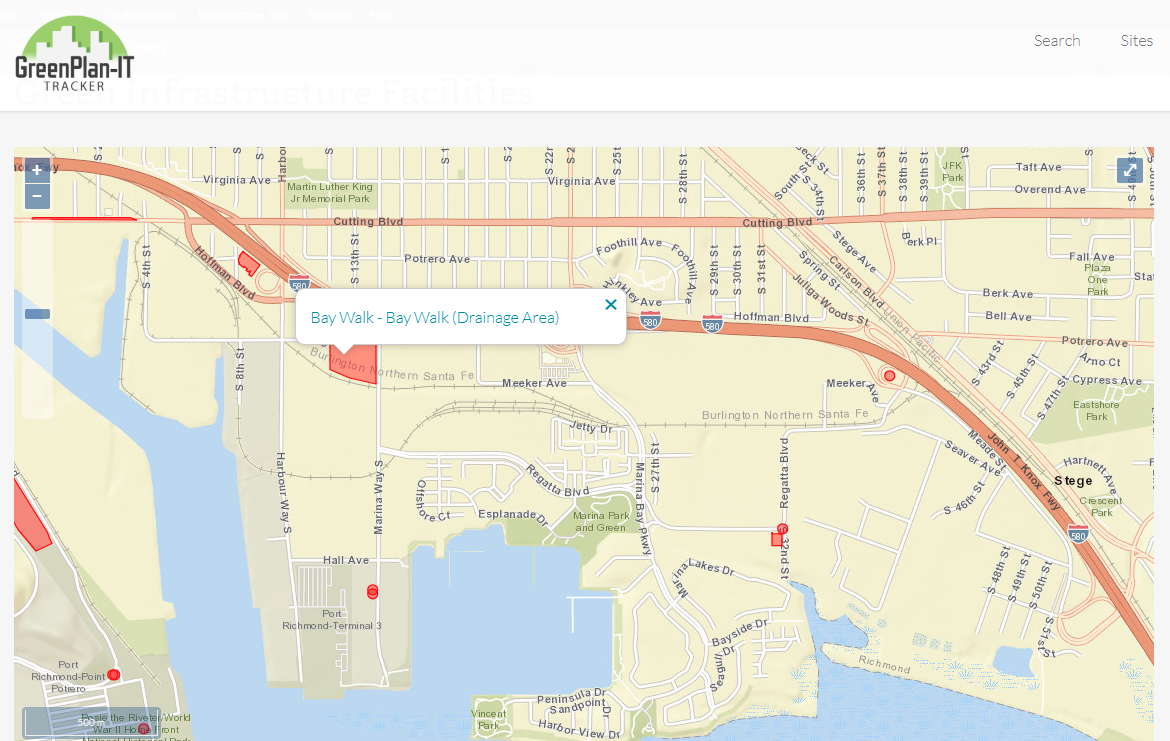
Figure 1 : The Richmond Waterfront and associated green infrastructure.
The GreenPlan-IT Tracker places green infrastructure facilities into their proper context. Figure 1 shows the Richmond waterfront with red areas marking drainage management areas associated with installed green infrastructure. Clicking on a polygon provides easy access to more information with another click.
Key Functions and Features
Detailed Information on a per-site basis

Figure 2: Detailed Information on facilities.
The tool records and displays critical information about the outputs of city planning and GI implementation for each installed facility. This includes specifics regarding the type, configuration, and geospatial information. It also records maintenance and monitoring logs that can be accessed from field locations: a key feature to help ensure that the installed facilities and the associated municipal expenditures continue to provide the value back to the community as designed.
Geospatial capabilities

Figure 3: Detailed geospatial designation of drainage management areas and treatment areas.
The Tracker offers the ability to generate polygons in the browser, associated with drainage management areas and treatment areas. These designated areas help to determine the effect of the GI facility when also combined with its type of treatment, the configuration of its associated features, and the location in the subwatershed.
Reporting information for inclusion in stormwater reports
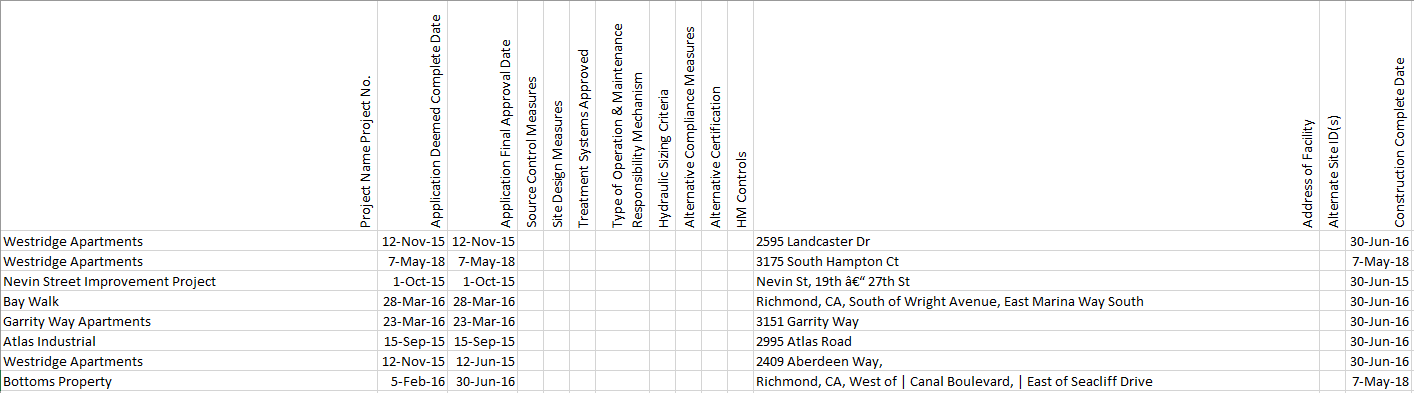
Figure 4: Information suitable for inclusion in stormwater reports.
The information stored in GreenPlan-IT reflects the information reported for individual green infrastructure facilities reported under the Provision C.3 of the Municipal Regional Permit, requiring the reporting of new development and redevelopment for regulated and special projects.
“Effectiveness reporting” for individual installations

Figure 5: Effectiveness Reporting by individual facility.
The system calculates effectiveness for individual installations. The system also calculates effectiveness on the basis of the type of green infrastructure, its specific design configuration, and its location. These factors are used to generate the effectiveness view on a per-site basis, as processed by EPA’s SWMM model in the modeler tool component, and then displayed on individual sites
Figure 5 above illustrates some sample effectiveness output. “Baseline,” in this figure, represents the estimated metrics without any GI. The columns showing “With LID” account for the effect of the individual facility. The calculated information displayed is influenced by the type of facility / BMP /LID, the details of its configuration (usually established for each green infrastructure type county-wide), and its specific location within the watershed. The SWMM model processes these inputs to determine how much infiltration of stormwater is increased and how much PCB would be removed with and without the given facility. Further information on any of the displayed items is available by hovering over the items.
“Effectiveness reporting” for the municipal green infrastructure portfolio

Figure 6: Effectiveness Reporting by jurisdiction.
Similar to the modeling based on individual facilities, the system also calculates effectiveness for the entire municipal jurisdiction on the basis of the city’s green infrastructure portfolio. The individual types of green infrastructure, their specific configurations, and their locations are collectively taken together and then processed by EPA’s SWMM model in the modeler tool of the toolkit, which employs an algorithm to calculate the collective effectiveness, which are the outcomes identified by the community in attenuating stormwater flow and filtering pollutants.
This jurisdictional view in figure 6 offers a very unique sense of the growing portfolio. The years mark the completion dates for construction of the individual green infrastructure facilities. This effectiveness reporting fosters understanding of the value of the city’s managed portfolio through a line chart that measures the increasing number of acres treated as the impervious landscape becomes more porous. Viewers, including community members and resource planners, can measure the contribution to the city’s overall attenuation of stormwater flow and pollutant load reduction in alignment with the city’s goals and permit requirements.
Mapping of sites for external use
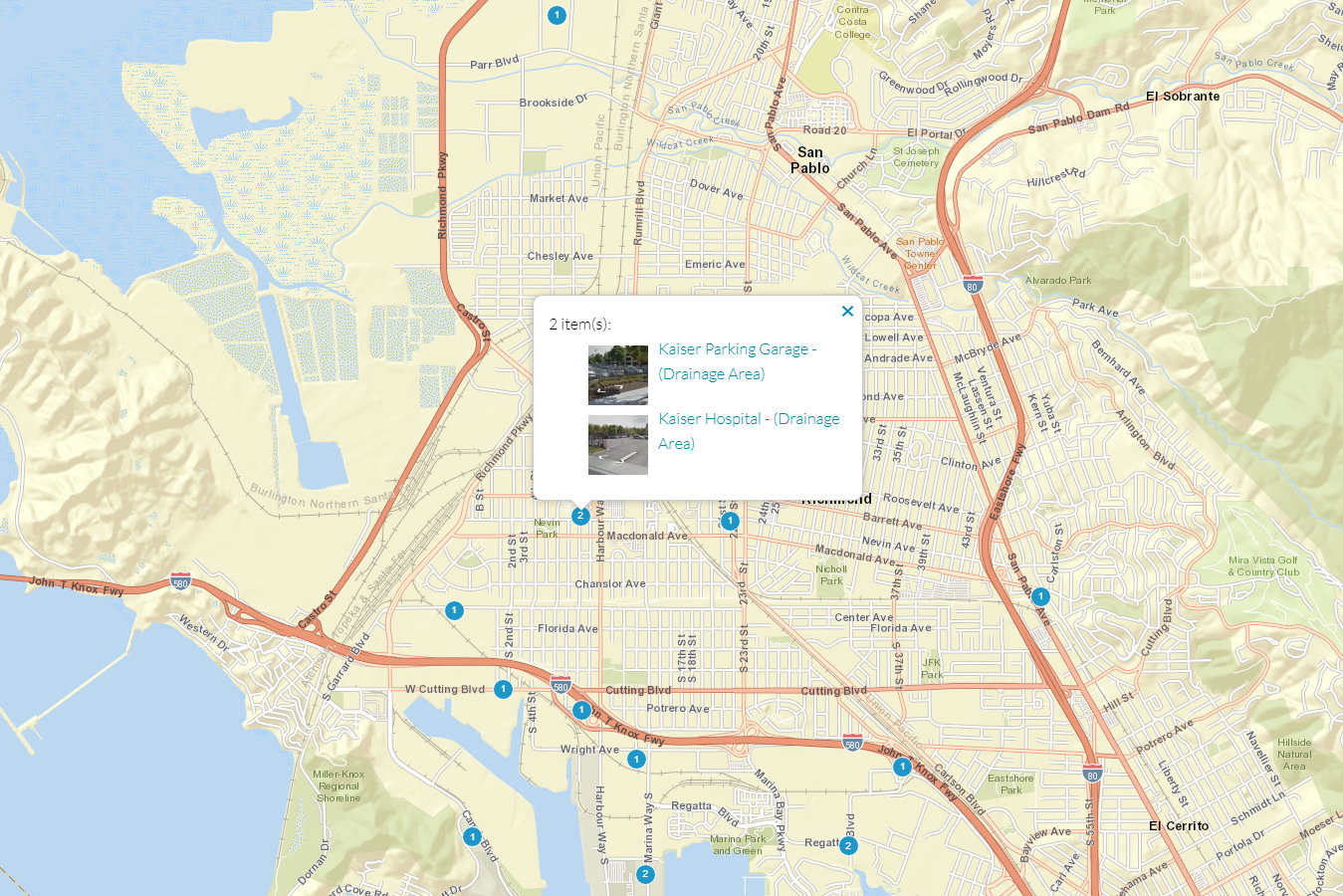
Figure 7: Embeddable map of the City of Richmond.
Sites entered into the system can be displayed by the municipality on dynamic Tracker maps that can, in turn, be embedded into the municipal website pages, staff reports, quarterly reports to the council, or any other regular reporting requirements to show the value, the outcomes of the city’s investment in green infrastructure.
Importing and exporting
Figure 8: List of sites with link to export data.
Importing new records about additions and changes to new or upgraded facilities is accomplished by entering data into the available forms. Or data can be provided to the tool’s stewards, SFEI, for reformatting and integration.
Exporting data is available for a given jurisdiction. After narrowing a list of sites to those in a selected jurisdiction, you may download the associated data, or transfer it to other platforms or data management systems as illustrated in figure 8. (You must have permission to view the data to be displayed.)
Mobile-enabled entry and editing
Figure 9: Mobile view of Maintenance and Inspection Logs
Responsive design allows technicians in the field to view, enter, and update information on their tablets or phones.
Licensing Plan

The Tracker is slightly different from the other modules in the GreenPlan-IT toolset. The Site Locator Tool, Modeler, and Optimizer are sophisticated, downloadable tools designed to help municipalities plan and assess their green infrastructure investments. They are freely available on the GreenPlan-IT website: http://greenplanit.sfei.org. Unlike other modules within the GreenPlan-IT toolset, the Tracker is not able to be distributed since it follows a software-as-a-service model. Its value lies in its accessibility as an easy-to-use, always-available centralized website and database.
To make GreenPlan-IT Tracker accessible to even the most budget-constrained municipality, we have scaled the cost for ongoing support and maintenance of the toolset to the number of sites entered into Tracker by the municipality. In other words, the fewer the sites the municipality has in its portfolio of installed green infrastructure, the lower its licensing costs.
The licensing fees will cover costs for hardware (server and networking equipment), bandwidth, software upgrades, basic application enhancements, and customer support.
The tiers for ongoing support are as follows:
- 1-100 Sites: $1,000 / year
- 101-500 Sites: $2,000 / year
- 501-2000 Sites: $3,000 / year
- 2001 - 5000 Sites: $4,500 / year
- > 5000: $6,000 / year
In this way, a relatively meager investment is leveraged at great value to the users and the communities they serve. The team will work with municipal managers to re-assess the licensing fees on an annual basis to ensure that a fair value is delivered.
Roadmap
This licensing structure supports the Tracker tool’s upgrades as necessary and the team’s availability to attend to user needs beyond the term of the EPA-funded contract. While we can forecast which needs might arise, we cannot always predict with great accuracy which should receive immediate attention. However, based on feedback received and opportunities already identified, what follows is a forecast of further development for the GreenPlan-IT Tracker.
Client-Base Expansion
With interest in GreenPlan-IT remaining high, the SFEI team plans for continued growth of the Tracker tool, along with the Site Locator, Modeler, and Optimizer.
Cities will continue to use Tracker to record additional sites and leverage the output for reporting. The team will support additional cities who wish to avail themselves of these features. Cities might also test their assumptions about the effectiveness of their managed portfolio of green infrastructure against the SWMM-based modeling output available to them. As implementation expands beyond the cities already using the tool, we can anticipate changes to the tool. It is designed to be extensible to customization as needs are expressed by the user base. Those changes might include some of the following ideas:
Customized Charting
The charts available to users of the tool are solid but limited. We anticipate that cities may wish to develop their own items to be charted based on as-yet-to-be determined factors.
Regional Analysis
With additional cities contributing to the Tracker, analyses conducted beyond the individual counties will be possible. The calculations for effectiveness at a more regional scale can be added to aid local decision makers who may wish to coordinate efforts at a broader scale.
Additional Modeling
The SWMM-based modeling integrated into the Tracker is a useful addition. It exposes a handful of calculations deemed to be useful to stewards of the green infrastructure. However, there are additional materials that can be calculated, shared, and visualized within the tool.
Project: Healthy Watersheds, Resilient Baylands
Another project funded by EPA’s Water Quality Improvement Fund, “Healthy Watersheds, Resilient Baylands,” will address opportunities near the Bay’s edge to address water quality needs through the use of ecologically focused solutions. GreenPlan-IT will be enhanced within this project to deliver ecologically informed hydrologic assessments of the urban landscape. At the same time, there are other project proposals in the works that may yield new enhancements for the Toolset.
Technical Specifications
The system includes primary data sources, imported or manually inputted into the system. In figure 11 below, this information falls under “Direct Inputs.” This directly contributed information is available for output via exports. The system also features information calculated or derived from the primary data, using them as inputs to a model, designed to determine the overall effectiveness, the outcomes of the green infrastructure portfolio in relation to the City's goals and permit requirements. This information is termed “Derived Outputs” in the figure below because it is the result of processing the accumulated raw data that the tool stores and turning it into the needed information for reporting out on monthly, quarterly or annual time intervals to city departments, community groups, regulators and the city council.
Figure 11: Conceptual ERD for GreenPlan-IT Tracker.
The ERD is conceptual in the context of the database because the content management system is non-normalized. It does not adhere to the conventional standards of a database designed specifically for this purpose. This allows the database versatility and adaptability. The section dedicated to effectiveness reporting does describe a more conventional normalized database model. In either case, we do document the fields nevertheless in the following collection of resources.
Platform
The Tracker is designed using open-source tools to minimize software and maintenance costs, while affording the greatest possible transparency. Documented below are the specifications for the operating system, application, scripts, database, and data structures.
Primary Application
- Operating system: Ubuntu
- Database: Postgres
- Content management system: Drupal
- Geospatial engine: PostGIS
- Geospatial visualization: OpenLayers
The primary application permits role-based security by virtue of the Drupal content management system (CMS). PostGIS and Openlayers, working together, offer geospatial enhancements to the CMS that offer advanced in-browser feature editing. The native reporting features offer sustainable and customizable reporting outputs.
Effectiveness Reporting Submodule
- Operating system: Ubuntu
- Database: Postgres
- Scripting Language: Python
- Modeling engine: SWMM5
Summary of effectiveness reporting processing
One novel innovation of the GreenPlan-IT Tracker is the integration of EPA’s SWMM5 model into the Tracker online database. The scripts are written in Python using a wrapper to call the EPA's SWMM5 model (https://pypi.org/project/SWMM5/). An unmodified version of SWMM5 handles all of the analysis. Meanwhile, the Python-based wrapper code manages the tasks, dynamically modifying a template SWMM input file, triggering SWMM via the wrapper library, parsing the output file, and updating the analytical database.
Detailed description
The processing proceeds in this fashion on a daily basis:
- Tasks are stored in the GPT database when any node is modified by Drupal (using short Drupal module written in PHP)
- Python, when run, retrieves the list of queued tasks from the database
- Duplicate tasks or tasks with insufficient input data are marked as such and ignored
- For each valid task, Python queries the database to get relevant input data, then modifies a "template" SWMM5 input file (just formatted text really). The template being manually created for each region/jurisdiction.
- The wrapper triggers SWMM5 to run using that modified input file and Python waits for it to finish.
- Once finished, Python parses the output report file (just formatted text), then uploads the relevant data back into the GPT database.
- The regional tasks are run similarly, except instead of just using one node to modify the input, it uses all the nodes within the jurisdiction.
Field specs
Primary Application
Watershed Characteristics
- TABLE: Watershed Identification
- Watershed_ID
- Char
- 24
- Watershed_Name
- Char
- 256
- Watershed_ID
Socio - Economic Characteristics
- TABLE: Site_Location
- City
- Char
- 60
- County_Code
- Char
- 5
- State_Code
- Char
- 2
- Zip
- Char
- 14
- Geocode_Latitude
- Char
- 10
- Geocode_Longitude
- Char
- 11
- Reference_Datum (Horizontal)
- Char
- (e.g., NAD83, WGS84)
- City
LID Characteristics
- TABLE: Identification
- Title
- Char
- 256
- Alternate_Site ID(s)
- Char
- 24
- Alternative_Certification
- Char
- 24
- Alternative_Compliance_Measures
- Char
- 24
- Description
- Char
- Long
- Name_of_Developer
- Char (Validated)
- 24
- Public/Private
- Char (Validated)
- 24
- Status
- Char (Validated)
- 24
- Total_Area_of_Land_Disturbed (Acres)
- Num
- Total_New_Impervious_Surface_Area (ft2)
- Num
- Total_PostProject_Impervious_Surface_Area (ft2)
- Num
- Total_PreProject_Impervious_Surface_Area (ft2)
- Num
- Total_Replaced_Impervious_Surface_Area (ft2)
- Num
- Total_Site_Area (Acres)
- Num
- Title
- TABLE: GI_feature_area
- Associated_LID_ID
- Char
- 24
- Geometry
- Char
- Long
- Location
- Binary
- KML
- Latitude
- Double
- Feature Centroid
- Longitude
- Double
- Feature Centroid
- Area
- Num
- Reference_Datum (Horizontal)
- Associated_LID_ID
- TABLE: Owner_Information
- Owner_type
- Char
- 24
- Owner_Name
- Char
- 50
- Owner_Contact
- Char
- 50
- Owner_type
- TABLE: Drainage_management_area
- Type_of_Treatment_HM_Controls_Inspected
- Char
- 24
- Location_Name
- Char
- 256
- Estimated
- Char
- 24
- Geometry
- Char
- Long
- Location
- Binary
- KML
- Latitude
- Double
- Longitude
- Double
- Reference_Datum (Horizontal)
- Type_of_Treatment_HM_Controls_Inspected
Design Characteristics
- TABLE: Infiltration_rates
- Capacity
- Num
- filter_rate
- Num
- Designed_to_Hold_Water_72_Hours
- Char
- 24
- Capacity
- TABLE: Soil_media
- Type
- Char
- 24
- Depth
- Num
- Num
- Type
- TABLE: Permitting_process
- Application_Deemed_Complete_Date
- Date
- Application_Final_Approval_Date
- Date
- Construction_Complete_Date
- Date
- Application_Deemed_Complete_Date
Costs
- TABLE: LID_costs
- Installation_cost
- Num
- Mainanence_cost
- Num
- Rehabilitation_cost
- Num
- Installation_cost
Maintenance Information
- TABLE: Event_Maintenance
- LID_ID
- Char
- 24
- Date
- Date
- Type_of_Operation_Inspection
- Char
- 24
- Inspection_Findings_or_Results
- Char
- Long
- Enforcement_Action_Taken
- Char
- Long
- Comments_Follow-up
- Char
- Long
- Activity
- Char
- Long
- Outcome
- Char
- Long
- Status
- Char
- 24
- LID_ID
Reports / Engineered Drawings
- TABLE: File_Attachments
- File_Attachment
- Binary
- Comments
- Char
- Long
- Date
- Date
- File_Attachment
Lookup Tables
TABLE: LID_Types
|
Code |
Description |
|
biornu |
Bioretention without an Underdrain |
|
biorwu |
Bioretention with an Underdrain |
|
ftpb |
Flow Through Planter Box |
|
inft |
Infiltration Trench |
|
prpv |
Permeable Pavement |
|
swwt |
Stormwater Wetland |
|
trbx |
Tree Box |
|
vgsw |
Vegetated Swale |
|
wtpd |
Wet Pond |
TABLE: Maintenance_Status
|
Code |
Description |
|
NM |
needs maintenance |
|
GC |
good condition |
|
SM |
scheduled for maintenance |
TABLE: Owner_type
|
Code |
Description |
|
CNG |
County Government |
|
COR |
Corporation |
|
CTG |
Municipality |
|
DIS |
District |
|
FDF |
Federal Facility (U.S. Government) |
|
GOC |
GOCO (Gov Owned/Contractor Operated) |
|
IND |
Individual |
|
MWD |
Municipal or Water District |
|
MXO |
Mixed Ownership (e.g., Public/Private) |
|
NON |
Non-Government |
|
POF |
Privately Owned Facility |
|
SDT |
School District |
|
STF |
State Government |
|
TRB |
Tribal Government |
|
UNK |
Unknown |
Effectiveness Reporting Submodule
The effectiveness reporting subsystem leverages EPA’s SWMM5 model to calculate a number of key outputs from the data within the system. The tables below are discrete from the functions associated with the general tracker application since these tables are specialized to hold SWMM-based parameters, input data, and output data.
Task tables
- TABLE: task
Table of all SWMM tasks. Populated by drupal on node update hook. Updated and run (or declined) by Python/SWMM scripts.
- taskid
- Integer
- Unique, non-null, primary key
- Autofill, sequential
- nodeid
- Integer
- Statuscode
- Text
- Matches key “statuscode” in table “statuslu”
- Only used when linked to regional tasks to track total treated drainage management area in regional run
- requestdate
- Timestamp
- processdate
- Timestamp
- finishdate
- Timestamp
- modelversion
- Text
- totaldma
- Integer
- TABLE: regionaltask
A table for tracking regional tasks, that is, a task aggregating a whole region (as opposed to individual GI installation). Does not track the model task itself, but each entry is linked to a task in the task table.
- regiontaskid
- Integer
- Unique, non-null, primary key
- Autofill, sequential
- regionid
- Integer
- Matches key “regionid” in table “regionlu”
- taskid
- Integer
- Matches key “taskid” in table “task”
- statuscode
- Text
- Matches key “statuscode” in table “statuslu”
- taskyear
- Integer
- tasktype
- Text
- To identify task if not by year (usually ‘baseline’ task or ‘all’ task)
- lasttaskid
- Integer
- Matches key “taskid” in table “task”
- Last completed task id if new task in queued or processing
Output Tables
- TABLE: runoffoverview
Summary of runoff quantity continuity. Will only be one row per task.
- runoffoverviewid
- Integer
- Unique, non-null, primary key
- Autofill, sequential
- taskid
- Integer
- Matches “taskid” in table “tasks”
- initiallidstorage
- Float
- Acre-feet
- evaporationloss
- Float
- Acre-feet
- infiltrationloss
- Float
- Acre-feet
- surfacerunoff
- Float
- Acre-feet
- finalstorage
- Float
- Acre-feet
- continuityerror
- Float
- totalprecipitation
- Float
- Acre-feet
- TABLE: pollutantoverview
Summary of runoff quantity continuity for pollutants. One row per task per pollutant tracked (which for now is only PCB).
- pollutantoverviewid
- Integer
- Unique, non-null, primary key
- Autofill, sequential
- taskid
- Integer
- Matches “taskid” in table “tasks”
- pollutant
- Text
- We only track PCB so value here will only be that, but leaving flexible in case that changes in the future
- initialbuildup
- Float
- Values in lbs (at least for PCB, only output we track for now)
- surfacebuildup
- Float
- Values in lbs (at least for PCB, only output we track for now)
- wetdeposition
- Float
- Values in lbs (at least for PCB, only output we track for now)
- sweepingremoval
- Float
- Values in lbs (at least for PCB, only output we track for now)
- Infiltrationloss
- Float
- Values in lbs (at least for PCB, only output we track for now)
- bmpremoval
- Float
- Values in lbs (at least for PCB, only output we track for now)
- surfacerunoff
- Float
- Values in lbs (at least for PCB, only output we track for now)
- remainingbuildup
- Float
- Values in lbs (at least for PCB, only output we track for now)
- continuityerror
- Float
- TABLE: runoff
Detailed runoff statistics. This and following tables designed to handle multiple rows per task, for each LID, for each subcatchment, or combination thereof as necessary.
- runoffid
- Integer
- Unique, non-null, primary key
- Autofill, sequential
- taskid
- Integer
- Matches “taskid” in table “tasks”
- subcatchmentid
- Integer
- Matches “id” in table “subcatchments”
- I don’t think region_id is needed since subcatchment_id should be unique itself
- totalprecipin
- Float
- Inches
- totalevapin
- Float
- Inches
- totalinfilin
- Float
- Inches
- totalrunoffin
- Float
- Inches
- totalrunoffgal
- Float
- Gallons (technically SWMM outputs in mega-gallons, note to self, either convert before storing value or be sure to note it’s not in straight gallons)
- peakrunoffcfs
- Float
- CFS
- runoffcoeff
- Float
- TABLE: lidperformance
Detailed LID statistics.
- lidperformanceid
- Integer
- Unique, non-null, primary key
- Autofill, sequential
- taskid
- Integer
- Matches “taskid” in table “tasks”
- subcatchmentid
- Integer
- Matches “subcatchmentid” in table “subcatchments”
- lidtype
- Text
- totalinflowin
- Float
- Inches
- evaplossin
- Float
- Inches
- infillossin
- Float
- Inches
- surfaceoutflowin
- Float
- Inches
- drainoutflowin
- Float
- Inches
- initialstoragein
- Float
- Inches
- finalstoragein
- Float
- Inches
- continuityerror
- Float
- TABLE: washoff
Detailed washoff statistics.
- washoffid (need better name)
- Integer
- Unique, non-null, primary key
- Autofill, sequential
- taskid
- Integer
- Matches “taskid” in table “tasks”
- subcatchmentid
- Integer
- Matches “subcatchmentid” in table “subcatchments”
- pcblbs
- Float
- PCB in lbs
- May potentially be more columns for other pollutant types, but would follow same format (for now PCBs are only ones we track)
Lookup tables (and also subcatchment)
- TABLE: statuslu
Status types (e.g. “Processing”, “Declined”, “Error”).
- statuscode
- Text
- Unique, non-null, primary key
- statusname
- Text
- statusdesc
- Text
- TABLE: regionlu
Regions for different jurisdictions and/or SWMM model input. Right now should only hold “Richmond”.
- regionid
- Integer
- Unique, non-null, primary key
- regionname
- Text
- regiontid
- Integer
- TID for jurisdiction as tracked in Drupal
- TABLE: subcatchment
Watershed subcatchment geometries.
- subcatchmentid
- Integer
- Unique, non-null, primary key
- subcatchmentname
- Text
- regionid
- Integer
- Matches key “regionid” in table “regionlu”
- geom
- Geometry (EPSG 3310)
